
Designing Scalable Data Pipelines in the Cloud
Cloud Architecture & DevOps

In our previous post, we explored strategies for creating secure CI/CD pipelines—a critical step to ensure your applications are delivered reliably and safely.
Today, we’re shifting gears to tackle another essential topic: building scalable data pipelines in the cloud. These pipelines are the foundation of modern analytics and decision-making, helping organizations handle massive data volumes and extract meaningful insights.
This post is part of a larger series designed to take you from foundational concepts to expert-level strategies in cloud architecture and DevOps. You can find a more detailed version of this article over on my Medium for additional depth and examples.
Why Scalable Data Pipelines Matter
Businesses today depend on data. Whether it’s powering machine learning, informing decisions, or driving real-time analytics, scalable pipelines ensure you can handle data growth without disruption. They allow you to:
Integrate new data sources effortlessly.
Manage surges in data volume without performance issues.
Foster collaboration between data engineers, analysts, and developers.
A well-designed pipeline supports modern DataOps and DevOps practices, embedding security and compliance into the data flow from the start.
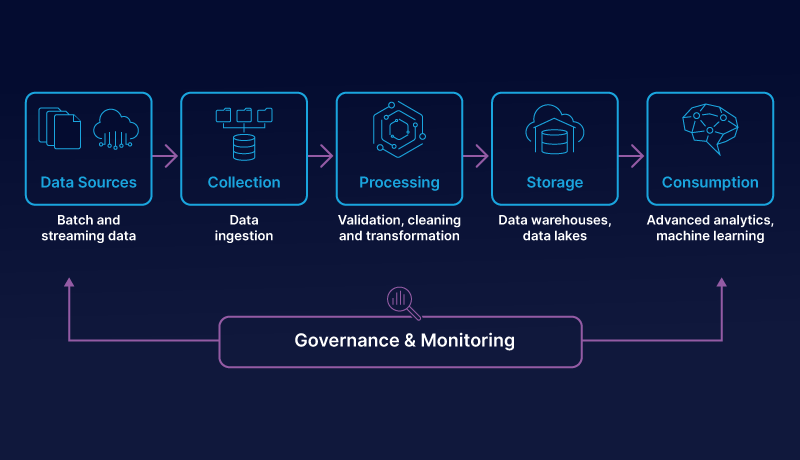
The Core Elements of a Data Pipeline
At a high level, a data pipeline consists of these stages:
Ingestion: Collect data from sources like IoT sensors, APIs, or transactional databases.
Transformation: Clean, normalize, and enrich data into usable formats.
Storage: Use scalable data lakes, warehouses, or NoSQL databases.
Processing & Analytics: Run batch or real-time analytics, machine learning models, or BI queries.
Orchestration & Monitoring: Manage workflows, detect errors, and adapt to changing workloads.
Each stage must be independently scalable. Event-driven architectures, microservices, and serverless solutions are excellent tools for achieving this flexibility.
Key Cloud Tools for Scalable Data Pipelines
You don’t need to reinvent the wheel—cloud providers and open-source tools offer robust solutions for ingestion, ETL, and orchestration. Here are some key examples:
Ingestion Services
AWS Kinesis: Real-time, fully managed data ingestion that scales seamlessly.
Azure Event Hubs: High-throughput streaming platform for millions of events.
Google Cloud Pub/Sub: Scalable messaging service for decoupling senders and receivers.
Apache Kafka (Open-Source): Popular for high-throughput streaming but requires more operational effort.
ETL (Extract, Transform, Load) Services
AWS Glue: Automates ETL with serverless jobs and data cataloging.
Azure Data Factory: Cloud-based service for data integration and transformation.
Google Cloud Dataflow: Unified stream and batch processing built on Apache Beam.
Apache Airflow & Spark (Open-Source): Powerful tools for ETL workflows, though they require more management.
Steps to Build a Scalable Cloud Data Pipeline
Define Your Strategy: Identify data sources, transformations, and destinations. Is this a streaming or batch pipeline? What performance and latency goals do you have?
Set Up Ingestion: For real-time scenarios, use AWS Kinesis. For batch workloads, consider managed uploads to S3 or Azure Blob Storage.
Automate Metadata Management: Use tools like AWS Glue Data Catalog to auto-discover data schemas and maintain a central view of datasets.
Transform Your Data: Write ETL scripts to clean and normalize data. Use Glue’s development endpoints or Spark for large-scale jobs.
Choose the Right Storage: Store raw data in scalable solutions like Amazon S3 or Google BigQuery. Design for schema flexibility to accommodate new sources.
Orchestrate Workflows: Automate your pipeline using tools like AWS Step Functions or Apache Airflow. Use triggers to kick off ETL jobs when new data arrives.
Integrate Machine Learning: Incorporate AI models for tasks like anomaly detection or quality checks. Use historical patterns to predict future data loads and scale resources proactively.
Monitor & Alert: Leverage tools like CloudWatch or Azure Monitor to track pipeline health, detect bottlenecks, and send real-time alerts.
Don’t Forget Security
As your data pipeline scales, so must your security measures:
Encryption: Use TLS for data in transit and KMS for data at rest.
Access Controls: Apply IAM policies with least-privilege access.
Network Isolation: Keep critical components in private subnets and protect exposed endpoints.
Compliance: Integrate continuous compliance checks to meet regulations like GDPR and HIPAA.
Modern Approaches: DataOps & DevOps
A cultural shift is driving modern data pipelines. Teams are treating pipelines as code: version-controlling ETL scripts, peer-reviewing logic, and integrating changes continuously. This reduces friction, fosters collaboration, and accelerates innovation.
Best Practices for Scalable Pipelines
Design for Elasticity: Use serverless and microservices to scale components independently.
Offload Operations: Use managed services like AWS Glue and Kinesis.
Automate Everything: From schema detection to transformations, reduce manual effort.
Leverage AI: Optimize scaling, detect anomalies, and streamline processes with machine learning.
Enforce Security: Protect your data with robust encryption, IAM policies, and network controls.
Continuously Monitor: Stay ahead of performance issues with real-time logs, alerts, and dashboards.
What’s Next?
Building scalable pipelines is just one piece of the puzzle. In our next post, we’ll explore automating infrastructure and security audits. You’ll learn how tools and AI-driven analyses can keep your systems secure and compliant as they scale.
To dive deeper, you can check out the full version of this post on Medium. See you next time!